PDF 래스터 메모리 폭주로 인한 장애 포스트모템
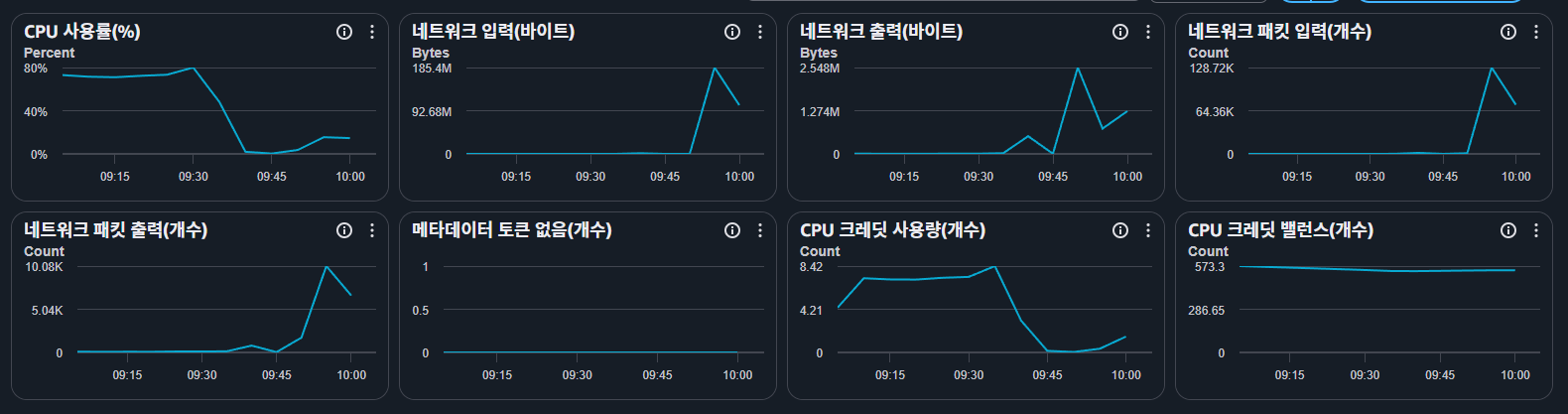
A0 도면 PDF 한 건의 업로드가 어떻게 4GB 호스트 전체를 멈춰 세웠는지, SSH 가 죽은 인스턴스를 어떻게 진단했는지, 그리고 무엇을 고쳤는지에 대한 기록. 트리거 및 문제 현상 연세대 졸업전시 아카이브의 admin 기능 중에는 "학생 작품 PDF 업로드"가 있다. 업로드된 PDF 는 서버가 페이지별로 래스터화(pdfjs + @napi-rs/canvas) → WebP 인코딩(sharp) → S3 업로드 → 페이지당 작품(work) 레코드 등록까지 처리한다. admin 이 건축 도면 PDF 를 업로드하던 중(네트워크 인바운드 158MB 스파이크) 다음 증상이 동시에 발생했다. 운영 서비스와 dev 서비스(같은 EC2 의 별도 컨테이너) 둘 다 접속 불가 — 브라우저에는 빈 흰 화면 EC2 콘솔의 Instance Connect 접속 실패: 그런데 EC2 상태 검사는 3/3 통과, CloudWatch CPU 는 75% 에 고정된 채 내려오지 않음 인스턴스 재부팅 직후에도 (체감상) 동일 증상 지속 "실행 중인데 아무것도 안 되는" 상태. 인스턴스: t3.medium (2 vCPU / 4GB RAM / 스왑 없음). 원인 업로드 받은 PDF 파일을 이미지로 변환하는 전체 파이프라인을 살펴보자. API 라우트()가 원본 PDF 를 S3 에 보관한 뒤, 페이지를 하나씩 래스터 → WebP 변환 → S3 업로드한다. 핵심인 의 사고 당시 코드 전문: convertImageForUploadconvertImageForUploadPDF 페이지 수 초과: ${pageCount} (최대 ${MAXPDFPAGES}) 방어 장치가 없었던 게 아니다. 파일 크기 50MB 상한, 페이지 수 40 상한, 페이지를 한 장씩 처리하는 generator 구조, 업로드 실패 시 S3 롤백까지 갖춰져 있었다. 그러나 이 모든 가드가 "페이지 수"와 "파일 크기"를 제한할 뿐, 페이지 한 장의 픽셀 수는 어디에서도 제한하지 않았다. 그리고 래스터 배율은 상수였다. 주석의 가정은 "A4 (595×842pt) 기준 2380×3368px — 이후 WebP 변환 단계의 MAXDIMENSION(2600px) 다운스케일과 맞는 적정 해상도"였다. 일반 문서라면 합리적인 값이다. 문제는 건축 도면(또는 전시에 사용되는 패널)은 A4 가 아니라는 것. A0 시트(841×1189mm = 2384×3370pt)를 scale 4 로 래스터하면: | | A4 (가정) | A0 (실제) | |---|---|---| | 페이지 크기 | 595×842pt | 2384×3370pt | | scale 4 래스터 | 2380×3368px | 9536×13481px | | 픽셀 수 | 8M px | 128.5M px | | RGBA 원시 버퍼 | 32MB | 514MB | 여기에 pdfjs 내부 오브젝트 + PNG 인코딩 버퍼가 얹히면 페이지 한 장 처리에 1GB 에 근접한다. 페이지를 async generator 로 한 장씩 순차 처리하고 있었지만, 한 장의 피크가 호스트 가용 메모리를 넘으면 순차 처리는 의미가 없다. 스왑이 없는 4GB 호스트에서 이 할당이 일어나자: 1. Node 프로세스가 메모리를 빨아들이며 페이지 캐시가 증발 → 모든 프로세스가 디스크 re-read 로 스래싱 2. CPU 는 GC + 스래싱으로 천장에 고정 (커널 OOM killer 가 정리해줄 만큼 명확한 초과는 아니어서 더 오래 끌었다) 3. sshd 포함 모든 유저랜드가 사실상 정지 — Instance Connect 실패 4. nginx 는 TCP accept 는 받지만 upstream 이 응답하지 못함 → 빈 응답 (빈 흰 화면의 정체) 5. 커널/네트워크 스택은 살아 있으므로 EC2 상태 검사는 통과 — "실행 중인데 죽은" 상태 완성 원인 진단 과정 SSH 가 죽은 인스턴스는 진단 수단이 제한적이다. 실제로 사용한 경로를 순서대로: 1. 장애 유형 분기 — "어떻게 안 되는가"부터. DNS 오류 / timeout / refused / 5xx / 빈 응답은 각각 다른 레이어를 가리킨다. 외부에서 fetch 해보니 TLS 연결은 성립하는데 본문이 비어 있었다 ( 엔드포인트조차 같은 최소 응답도 없음). → 프록시까지는 살아 있고 그 뒤가 전멸. DNS 는 별도 확인으로 배제. 2. CloudWatch 그래프에서 타임라인 복원. 네트워크 인바운드 스파이크(158MB, 업로드) 직후 CPU 가 천장에 붙어 내려오지 않는 패턴. "업로드가 트리거한 서버 측 폭주"로 가설 수립. 상태 검사 3/3 통과는 커널 생존을 의미할 뿐 유저랜드 생존을 보장하지 않는다는 점이 중요했다. 3. 콘솔의 out-of-band 진단 도구. EC2 는 SSH 없이도 에서 인스턴스 스크린샷 캡처와 시스템 로그 가져오기를 제공한다. 재부팅 후 시스템 로그에서: 정상 부팅 + 로그인 프롬프트 도달 → OS 레이어 무결 → 직전에 정상 종료가 아닌 강제 정지가 있었다는 물증 디스크 관련 에러 없음 → 디스크 풀 가설 기각 4. 복구 후 사후 부검. 재부팅이 완료되자 SSH 가 살아났다 ("재부팅해도 안 된다"는 재부팅 완료 전 시도였던 것). 죽기 직전 마지막 로그가 pdfjs 래스터 경고였다. 코드의 와 업로드된 도면 PDF 의 페이지 크기를 대조하면서 원인이 확정됐다. 개선 1. 근본 원인 — 페이지 크기 기반 동적 scale () 고정 scale 을 버리고 2-pass 로 변경했다. 1차 패스: pdfjs 로 각 페이지의 pt 크기만 읽는다 (렌더 파이프라인을 타지 않아 비용이 거의 없다). 최장변이 (2600px, WebP 변환 단계의 MAXDIMENSION 과 동일)가 되도록 페이지별 scale 을 계산. A4 같은 작은 페이지는 상한. 2차 패스: scale 그룹별로 렌더. (래스터 라이브러리의 scale 이 문서 전역 옵션이라, 용지가 섞인 문서는 그룹별로 문서 핸들을 열고 페이지 순서대로 yield.) 결과 (A0 + A4 혼합 PDF 실측): | | 기존 (scale 4 고정) | 개선 (동적) | |---|---|---| | A0 원시 버퍼 | 514MB | 27MB (scale 0.77, 1835×2594px) | | A4 | 32MB | 27MB (scale 3.09) | | 최종 화질 | 2600px 다운스케일 | 동일 (다운스케일 입력이 이미 2600px) | 어차피 다음 단계에서 2600px 로 줄이던 픽셀들을 만들지 않게 됐을 뿐, 사용자 가시 품질은 변하지 않는다. 2. 폭발 반경 축소 — 같은 실수가 또 나와도 호스트는 살아남게 스왑 2GB 추가 — OOM 직행 대신 성능 저하로 완충. sshd 가 살아남을 시간을 번다. 컨테이너 메모리 상한 (, 코드로 관리): 초과 시 해당 컨테이너만 OOM-kill → 로 자동 재기동. 같은 호스트의 다른 서비스와 sshd 는 영향받지 않는다. Docker 로그 로테이션 — daemon.json + compose 양쪽에 명시 (환경 드리프트 방지). 3. 운영 후속 조치 SSM(Session Manager) 역할 연결 — SSH 가 죽었을 때의 비상 접속 경로 확보 CloudWatch CPU 지속 고점 알람 — "사이트가 죽고 나서야 아는" 상황 방지 교훈 상수에 박힌 가정은 입력이 가정을 벗어나는 순간 시한폭탄이 된다. "A4 기준 적정"은 도메인(건축 도면) 입력 분포를 만나는 순간 깨졌다. 입력 크기에 비례하는 자원 할당은 반드시 입력 기준으로 계산하고 상한을 걸 것. 변명을 보태자면, A4 사이즈를 기준으로 한 가정은 클로드가 알아서 만들어 낸 것이었다. 건축을 전공했던 나는 이미 전시용 패널은 사이즈가 엄청나게 클 것이라는 것을 알고 있었지만 프롬프트에 상세하게 지시하지 못했던 탓. EC2 상태 검사 통과 ≠ 서비스 생존. 커널이 살아 있다는 뜻일 뿐이다. 유저랜드 진단은 스크린샷 캡처 / 시스템 로그 / (미리 설정해 둔) SSM 같은 out-of-band 경로로. 스왑 없는 작은 인스턴스는 메모리 사고 시 우아하게 죽지도 못한다. 완충지대와 컨테이너별 상한으로 폭발 반경을 미리 설계해 둘 것.